
In defense of unit tests

A few years back, Guillermo Rauch—now the CEO of Vercel—tweeted a pithy assessment of automated testing:
Write tests. Not too many. Mostly integration.
— Guillermo Rauch (@rauchg) December 10, 2016
This inspired Kent C. Dodds to write that:
Integration tests strike a great balance on the trade-offs between confidence and speed/expense. This is why it's advisable to spend most (not all, mind you) of your effort there.
He further connected it to the alternatively-shaped "testing trophy," which puts more emphasis on static typing and integration tests than the traditional pyramid.
Neither of these takes are unique, but they're popular, memorable version of the idea. I've seen this happen both intentionally and inadvertently—in both cases, occasionally citing Guillermo or Kent.
Today I am going to talk about some of the unique value that unit tests can bring to a code base, and try to convince you not to skimp on this "lowest level" of automated tests.
Use the simplest tool for the job
A piece of advice that has served me well (I can't remember who said it or the exact wording, though, so if this sounds familiar, please let me know!) is to use the simplest/dumbest available tool for the job. The places I've seen this idea have the most impact have been web performance and automated testing.
In web performance, this usually manifests in two rules of thumb:
- If you can do it in CSS, do it in CSS.
- Don't try to outsmart the just-in-time (JIT) compiler.
In both cases, by choosing the simpler tool—CSS is not a general purpose programming language; and JITs are remarkable optimizing compilers of straightforward code, which also tends to be easier to read—allows the browser to make assumptions or inferences that produce faster results.
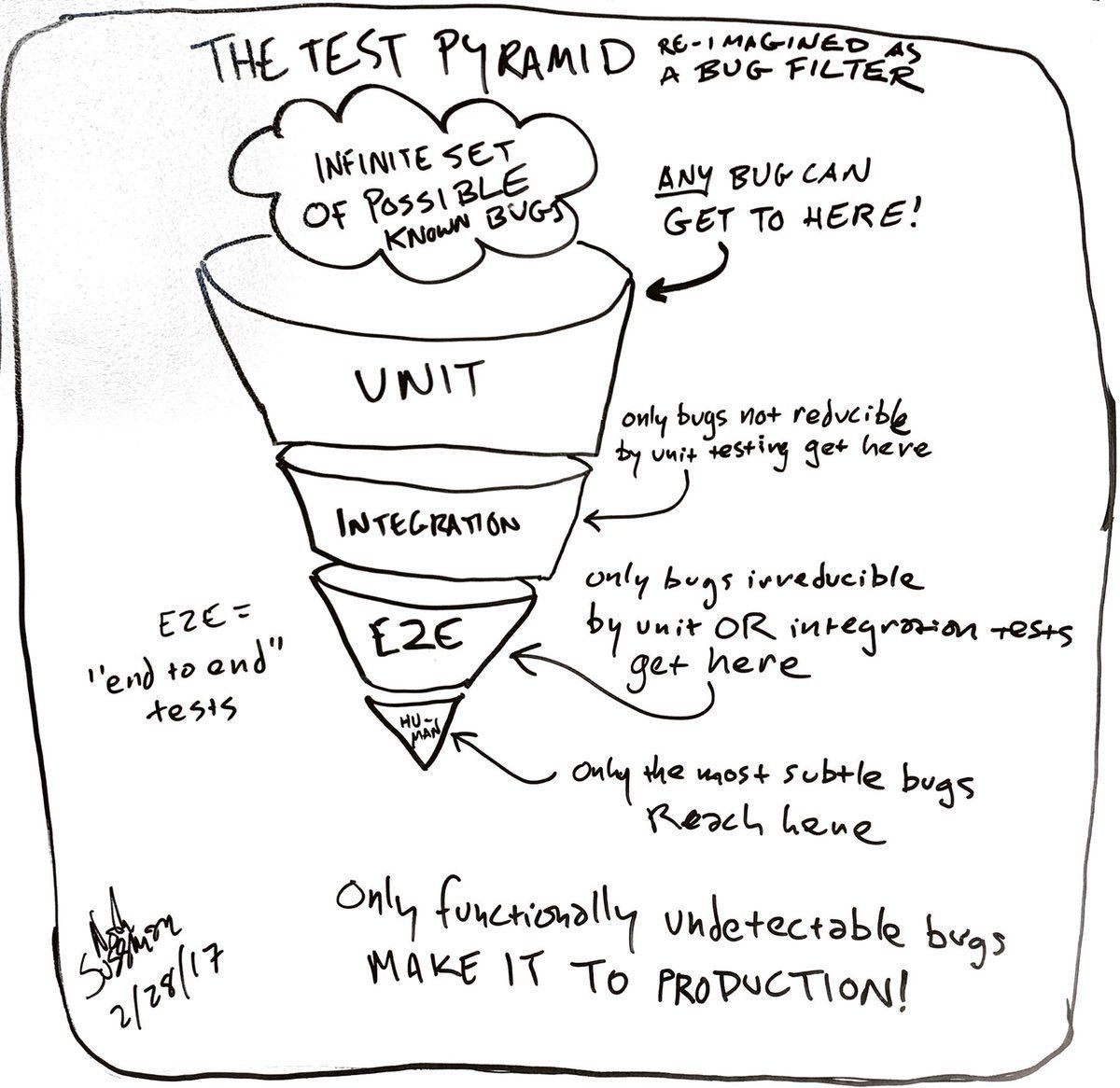
In testing, this is another statement of Noah Sussman's "bug filter of testing" model: if you can prevent an issue with a unit test, use a unit test.
But why? The reason turns out to be the same: the simpler the tool, the more assumptions we can make and the faster we can get results. With each new layer of complexity, tests get slower, flakier, and have more risk of interdependencies. They typically get harder to run locally, adding to the feedback loop for developers.
For example, many frameworks, especially those with "active record"-style ORMs, make it easy to write integration tests that use a real database. This test database becomes a shared resource and point of contention between the tests, reducing parallelism, as well as introducing new work—and often new processes and context switches—that the tests must do to run successfully.
Performance of a test suite matters immensely. The longer it takes to run tests—assuming they're even reasonable to run locally—the more likely it is to knock an engineer out of flow, or lead to distractions. This often results in engineers not running or relying on the test suite often, and only getting feedback from a continuous integration (CI) system.
Unit tests are by far the fastest, usually being limited to using memory and CPU, and most parallelizable type of tests. An old coworker (a different Noah) used to say that anything over 15 seconds was too slow—a threshold I initially dismissed but have come to agree with. If you're accustomed to writing tests that use databases, this may not even seem possible! Not only is it possible, being able to run some or even all of a test suite frequently while coding is amazing. Tests can become an integral part of the development workflow.
Unit tests are the first consumer of your code
Regardless of whether you're writing unit tests before the code, as in strict test-driven development (TDD), or as you go: unit tests are the first opportunity to use the code. Unit tests let you experience using a module's API—and, I suspect, encourage modularity. If something is hard to test, using a module's public API, it will likely be hard to use.
Unit tests are the only layer of testing that can give you immediate, direct feedback on a module's API, giving you a chance to improve it.
A common example is a module that makes HTTP requests. Ideally, tests should cover both successful and failed responses, whether they failed because of the network or because the status code was unexpected. In some languages, like Python or Ruby, this can be accomplished with monkeypatching, but doing so requires understanding the implementation details of the module—i.e. it's not possible with a black-box test. In other languages, or to maintain the black-box nature of the tests, we can apply dependency inversion to give ourselves a way to use a mock—totally in-memory and with known behavior—HTTP client:
import "net/http"
func GetPrices() (Prices, error) {
res, err := http.Get("http://price-service/api")
// ... etc ...
}This is currently simple to use, but difficult to test. A more testable version of this module might involve a more configurable API:
import (
"context"
"net/http"
)
type httpRequester interface {
Do(*http.Request) (*http.Response, error)
}
type PriceService struct {
serviceURL string
client httpRequester
}
func New(url string, client httpRequester) *PriceService {
if url == "" {
url = "some-default-url"
}
if client == nil {
client = http.DefaultClient
}
return &PriceService{
serviceURL: url,
client: client,
}
}
func (ps *PriceService) Get(ctx context.Context) (*Prices, error) {
req := http.NewRequestWithContext(ctx, http.MethodGet, ps.serviceURL, nil)
resp, err := ps.client.Do(req)
// ... etc ...
}This seems more complex, more work for consumers, and certainly it's more lines of code! However, by inverting this API and configuring our dependencies, we get two major benefits:
First, it's configurable. While we may use http.DefaultClient as the, well, default client, we can use any HTTP client—real or fake—at runtime. If we want to add a tracing HTTP client, or set up default timeouts, we can do that at runtime when we create our *PriceService (often in main.go). We can also set the URL explicitly, letting us pick different URLs in different environments easily, without needing to know internal details like what environment variable to set.
Secondly, the new version is, itself, more mockable! Package-level functions in Go can be a pain to test, partly because we tend to import and use them directly. Applying the same "make it configurable" advice lets us avoid that:
// the old version
func NeedsPrices(ctx context.Context) (*Result, error) {
prices, err := priceservice.GetPrices(ctx)
// ... etc ...
}
// the intermediate version
func NeedsPrices2(ctx context.Context) (*Result, error) {
svc := priceservice.New("", nil)
// ... etc ...
}// the new, more testable version
type priceGetter interface {
GetPrices(context.Context) (*priceservice.Prices, error)
}
type DependsOnPriceGetter struct {
PriceGetter priceGetter
}
func (dopg *DependsOnPriceGetter) NeedsPrices(ctx context.Context) (*Result, error) {
prices, err := dopg.PriceGetter.GetPrices(ctx)
// ... etc ...
}The result is that not only does each layer of our stack becomes more unit testable—meaning more of the tests can be thorough, reliable, and fast—but we end up with a more future-proof, flexible API that is more likely to be able to handle use cases we haven't imagined yet.