
Conceptual, Logical and Physical Data Models
Conceptual, logical, and physical data models has proven to be one of the most valuable things I've learned recently

The vocabulary of conceptual, logical, and physical data models has proven to be one of the most valuable things I've learned in the past few years. Understanding and using the distinction between these layers or steps in data modeling helps design better—more scalable, more comprehensible, more maintainable—applications.
Conceptual Data Models
"Conceptual" data models are the highest layer, and the best place to start. These describe the major entities in a system and their relationships to each other, without worrying about the details of each one. Think of a "boxes and arrows" diagram—that's the level of detail at this layer.
Let's look at an example of something similar to GitHub or Trello: a tool that helps a user manage several "projects," and choose to create a public profile page that may feature various projects. A first pass at our conceptual data model may end up looking like this:
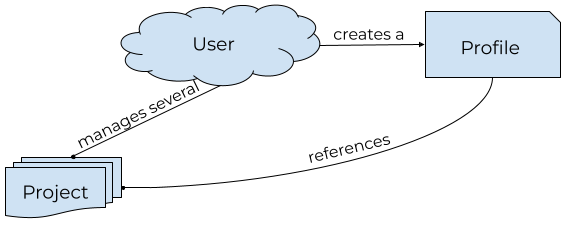
There are a few things to note in this diagram:
- There is no detail about any kind of database tables or foreign keys.
- There isn't even detail about what is included in a Project or a Profile.
- The relationships are described with verbs other than "to have" or "belong to." As a user, I don't merely possess a project, I manage it. I don't merely have a profile, I create it.
- The cardinalities of the various entities are established: many projects per user—represented by lines ending in dots rather than arrows—but only one profile per user.
Creating or updating a conceptual data model is a cross-functional task—product, engineering, design, data, and even subject-matter experts should all contribute at this level. This is an opportunity to employ ubiquitous language and ensure that everyone has a shared understanding of what these entities represent. Changes at the conceptual level—e.g. a change to the cardinality of a relationship, or creating a new entity—are possible but should not be undertaken lightly, since they are likely to have significant cascading effects on the rest of the software system.
Logical Data Models
"Logical" data models are the next layer down, and the place where we start to flesh out what our models will actually look like. We are still, at this layer, not writing code yet—and we will see why in the next section.
Logical data models tell us what attributes actually exist for a given entity. For example, we can look more closely at the "Project" model. What makes up a project?
- The project name
- A description
- A relationship to a managing user
- Note that this is not a "foreign key." Only SQL databases have those.
- Possibly a due date
- Percent complete
- Tasks
We can also look at what makes up a user:
- A unique username
- One or more email addresses
- One or more authentication methods, like a password or OAuth connection
Logical data models provide an important point of agreement between different functional groups, like a product engineering team and a data team. Changes at this level are likely to have at least some cascading effects. As long as stakeholders agree on this "shape," the risk of those effects causing problems is low.
This is also where we can start asking more nuanced questions. Do we need more than one email address? Are "Tasks" really their own entity? If we want to make changes, for example to add premium features, is billing information part of the user, or the project? Do some projects need to be designated as "premium" or does the user become premium? Decisions like this will potentially be difficult to reverse, and may constrain product options in the future, so they should be made cross-functionally and with care. Most importantly, though, they should be made consistently. If one part of the system builds billing into the user while another part of the system—possibly managed by another team—assumes that billing should be per-project, there may be irreconcilable design choices.
Physical Data Models
Physical data models are the actual implementation. At this layer, we have actual code, actual database tables, actual protobuf messages. There are almost always multiple physical data models for any logical model: a database model and a CRUD API are different implementations of the same logical model.
Looking at our logical model of a user, we can imagine how it might look in a JSON API response:
{
"username": "jsocol",
"emails": ["jsocol@example.com"],
"authMethods": [{ "kind": "password", "hash": "$2b$12$BRrjrm2AJof..." }],
}Or we can implement it in a Django model:
from django.db import models
class User(models.Model):
username = models.CharField(max_length=127, unique=True)
password = models.TextField(null=True, blank=True, default=None)
class UserEmail(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE)
email = models.EmailField(unique=True)
class OAuthConnection(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE)
# ... etc ...Or in protobuf for gRPC:
message User {
string name = 1;
repeated string emails = 2;
repeated AuthMethod auth_methods = 3;
}
message AuthMethod {
enum AuthKind {
AUTH_KIND_UNSPECIFIED = 0;
PASSWORD = 1;
OAUTH2 = 2;
}
AuthKind kind = 1;
// ... etc ...
}We can see here how different physical representations, with different constraints, can vary. JSON and protobuf allow repetition, through arrays and repeated fields, respectively. SQL databases, however, typically do not allow an arbitrary number of values for one column, so instead we create a new database model, UserEmail. On the other hand, Django has an EmailField type that is more specific than using text or a string, while JSON and protobuf do not. In the database, the various authentication methods are implemented differently: password exists as a nullable database column on the User model, while OAuth connections are stored in their own table. Protobuf can use enum or oneof types to distinguish different methods, while JSON cannot.
Different affordances, constraints, and needs or priorities will lead to different physical models, often within the same parts of the system. And that's OK! As long as they are all representing the same logical data model, you'll always be able to map between the different physical models when you need to.
When am I Going to Use This?
Engineers, in my experience, tend to start with the physical data model. We use diagramming tools specifically designed for SQL databases. And if you're working on a solo project, that's probably fine.
Teams, however—and especially teams with different disciplines—will benefit from proactive data modeling with these layers in several ways:
- Consistent vocabulary for different conceptual entities will avoid miscommunications across teams or functions.
- Non-technical team members have an easier time engaging with the less detailed conceptual and logical models.
- Early agreement on conceptual and logical data models makes it easier for teams or engineers to work independently—they provide the "alignment" part of "aligned autonomy."
- Different physical models of the same logical model are much more likely to be interoperable in the future.
- Changes to conceptual or logical data models are easier to contextualize, making them easier to implement and their consequences more obvious.
- Major entities (e.g. "User") are easier to distinguish from implementation details (e.g.
UserEmailorAuthMethod).
Conceptual and logical data modeling need not be a huge effort. Conceptual data modeling can involve a meeting to create the model together with subject-matter experts, product, etc, or it can be a quick sketch of the major entities and an asynchronous gut check. Logical data modeling can involve enumerating all the attributes of every entity up-front, or it can happen just-in-time, which is a much smaller chunk of work, and something we often do tacitly anyway. And physical data modeling is the work of writing software that we're already doing.