
Building Extensibility into APIs from the Start
Making the right design decisions early in a project can have a huge impact on the ability to safely improve and evolve it over time.

Making the right design decisions early in a project—whether a piece of greenfield code, a network API like HTTP or gRPC, or a module API in a library or larger code base—can have a huge impact on the ability to safely improve and evolve it over time. Choices that will reduce update work and risk later are often no more—or only negligibly more—expensive than the alternatives. Once the code is written, however, even if only in a pull request, making it more extensible is now a form of churn that needs to be weighed. That is: the best time to make these choices is at the beginning, and the second best time may never happen.
Most of these design patterns are about leaving room to grow, and fall into one of two categories: leaving room for future (optional) parameters, and leaving room for future interfaces/endpoints/methods.
Leaving room for new parameters
First, let's consider an HTTP API that takes some arguments via query string parameters. Maybe it's a list or search method like GET /v1/search. With query string parameters, we have two decisions to make: how to handle missing parameters, and how to handle unknown parameters.
If our /v1/search endpoint supports a q parameter for the search query and a page parameter to paginate through results, we might have something like:
| Parameter | Required? | Default |
|---|---|---|
q |
yes | none |
page |
no | 1 |
If the q parameter is missing, we can't generate a meaningful search, so we might return an HTTP 400 Bad Request status, but if the page parameter is missing, we can safely assume it's the first page.
When we want to add a page_size parameter, the backwards compatible decision is to add it as optional, with a default that is the same size as the previous behavior. This makes page_size a safe parameter to add without updating any callers—and this is typical of HTTP GET endpoints, since all parameters are named and order typically doesn't matter. (The question of how you treat unknown parameters is about forwards compatibility and depends more on the audience and the acceptable failure modes for this API.)
Now let's consider a TypeScript API. This would be a library or module within a larger code base, rather than a network API. The smallest search method might look like:
const search = (query: string): Result[] => {
// fetch and return results
}Code sample 1.0: a single-parameter search function
Where should the page argument go? One choice is to make it a second parameter:
const search =(query: string, page = 1): Result[] => {
// etc
}Code sample 1.1: adding a page parameter to our search function
The second parameter is optional, with a default, which seems like what we want. But what happens when we add a third pageSize parameter?
const search = (query: string, page = 1, pageSize = 25): Result[] => {
// etc
}Code sample 1.2: a third positional parameter shows the limits of this approach
Callers now need to know which order to pass parameters in, and may need to set default values for page even though the API itself also sets the defaults.
On the other hand, if our initial API had made room for future parameters, it might have looked like:
const search = (query: string, { page = 1 }: { page?: number } = {}): Result[] => {
// etc
}Code sample 1.3: using an options object leaves room to grow
This version is a few keystrokes more complex than sample 1.1, but leaves us a place to add more optional parameters with defaults and let callers opt into exactly which ones they want to use. When we add a pageSize option to sample 1.3, we might refactor slightly:
interface Options {
page?: number
pageSize?: number
}
const search = (query: string, { page = 1, pageSize = 25 }: Options = {}): Result[] => {
// etc
}Code sample 1.4: the options object grows a bit, but still has defaults
(In TypeScript, this is more fixable than in most languages, by changing the second argument from a scalar type like number to a union type like number | Options. But preferring the options object also means being more explicit, which rarely hurts.)
Exactly how this looks will vary from language to language. In Python we might use keyword arguments; in Ruby we might use an implicit options hash.
def search(query: str, page=1, page_size=25) -> List[Result]:Code sample 1.5: a Python search function with optional kwargs
def search(query, page: 1, page_size: 25)Code sample 1.6: a Ruby search function with optional named parameters
In a language like Go, if we used an Options struct from the beginning, we can add to it (as long as the zero values are treated as "use the default"):
type Options struct {
Page int64
}
func Search(query string, opts *Options) ([]Result, error) {
if opts == nil {
opts = &options{};
}
if opts.Page == 0 {
opts.Page = 1 // start on the default pageCode sample 1.7: a Go search function with an *Options parameter
This works if we knew there were options right away. If not, or if the defaults do need to be set, we could extend the Search function with a variadic argument:
type Option func(*options)
type options struct {
page int64
pageSize int64
}
// WithPage sets the page of results to return
func WithPage(page int64) Option {
return func(o *options) {
o.page = page
}
}
// WithPageSize sets the size of the page to return
func WithPageSize(size int64) Option {
return func(o *options) {
o.pageSize = size
}
}
func Search(query string, opts ...Option) ([]Result, error) {
// set defaults
o := &options{
page: 1,
pageSize: 25,
}
// apply any options
for _, opt := range opts {
opt(o)
}Code sample 1.8: a Go search function with variadic options
This approach has one other advantage: variadic parameters can be left out when calling the function, unlike positional parameters. So if callers started out like Search("some query"), then adding options this way allows those callers to work without changes.
Leaving room for new interfaces and methods
Creating space for future expansion can also come down to effective naming practices. Matching the specificity of the name to the specificity of the thing that is named avoids overlap and inconsistency later.
Here's an example that comes from a real world need: ongoing customer communication—in this version of history, we'll start with just email first. (And let's ignore the challenge of ingesting inbound email messages! 😅) When building an API to get the history of customer communication, a list of "messages" that can only contain emails seems fine at first. But needs change, and when SMS is added later, we are faced with unpleasant options:
- Add another list of "sms messages," and rely on documentation and shared understanding that "messages" is only email.
- Add SMS messages into the "messages" list, even though they do not have the same properties as emails, and deal with consumers breaking.
However, if instead we name this initial list "emails" or "email messages", or if we add "type = email" to every message even though they are all email, we've left space for the future.
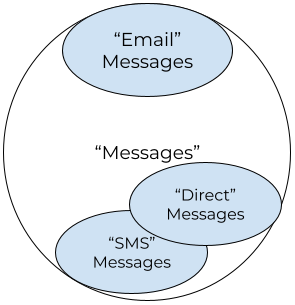
Picking names for an API is an art, but there is more downside to picking an overly-general name than an overly-specific one. Adding specificity is effectively namespacing. More general names (like CreateMessage or messages.create) take up the "common ground" within a namespace, while the more specific names (like CreateEmailMessage, messages.create_email, or even a smaller namespace like emails.create) are more narrowly scoped and take up less "space."
Similarly, a ListMessages method should either specify the type of message for each list entry—even if it only returns one type right now—or be named e.g. ListEmailMessages.
message ListMessagesResponse {
message Message {
enum MessageType {
MESSAGE_TYPE_UNSPECIFIED = 0;
EMAIL = 1;
/* Leaving room for more types in the future */
+ SMS = 2;
}
MessageType message_type = 1;
oneof message {
Email email = 1;
+ SMS sms = 2;
}
}
repeated Message messages = 1;
}
// or, narrowing the initial conceptual scope
message ListEmailMessagesResponse {
repeated Email emails = 1;
}Code sample 2.0: a diff demonstrating the value of namespacing in a protocol buffer message
Having this message_type enum, even if we only have one value for it, pushes a small amount of complexity into callers. Instead of:
emails, err := ListEmailMessages(&ListEmailMessagesRequest{})
for _, email := range emails.Emails {
// `email` is the full email message
}Code sample 2.1: iterating over an undifferentiated list is simpler
The caller should be checking the type, e.g.:
messages, err := ListMessages(&ListMessagesRequest{})
for _, entry := range messages.Messages {
switch (entry.MessageType) {
case MessageType.EMAIL:
// handle Email message
_ = entry.Message.Email
default:
fmt.Sprintf("unknown message type: %s", entry.MessageType)
}
}Code sample 2.2: iterating over a differentiated list means handling unknowns
Here again the difference in code is relatively small, meaning a negligible increase in time to deliver the initial version. However, it also means that we have introduced a layer of forward compatibility: the calling code can now "handle" new, unknown types of messages. It may not have anything to actually do with them, but it doesn't run the risk of encountering a list entry that it can't process and crashing.
There is a balancing act here. Namespacing does make identifiers longer—e.g. the infamous Java naming schemes like AbstractServiceLoaderBasedFactoryBean—and doesn't always add much value or clarity. (The most common problem I've seen is repeating the same specifier in two places, like messages.EmailMessage or metrics.NewMetric()—i.e. without adding any additional level of specificity.)
That said, I have never regretted adding a little bit of namespacing into names. At worst, it means autocomplete fills in a little bit more. For example, back in TodaysMeet, I added methods like get_user_messages and add_user_message for persistent but automatically-cleared messages. _user_ wasn't distinct from anything else at the time, but about 6 months later, there was a distinct type of message I had to add: persistent and requiring an action to dismiss. If I'd named the methods like get_messages, then I'd either have the misleading name get_messages (which didn't get all messages) along with the get_dismissable_messages; or would have had to change the method name to e.g. get_something_messages, introducing churn; or change the definition of get_messages to include all of them—a breaking change to the behavior.
Knowing when it's worth namespacing something is usually intuitive: it comes from your own experience of what tends to change, what tends to be general purpose or specific, etc; and it comes from your knowledge of the domain you're working in. Software for a bank that only offers checking accounts might still use CheckingAccount over Account, because in the domain of banking, we know there are many types of account that the business reasonably may end up offering eventually. And if it doesn't, there's no harm done—we've only specified a domain concept.